COG 2019 conference report
By popular demand, another conference report! Please note that this report is very biased towards the topics that are relevant for my PhD research, i.e. text generation and procedural content generation for games.
Between August 24 and August 27 2019 I visited the IEEE Conference On Games (COG) in London, UK. In previous years, this conference was called Computational Intelligence and Games (CIG). The last edition of this name was in Maastricht in 2018.
As opposed to Foundations of Digital Games, where most of the presented research seems to come from the social sciences, COG is more focused on the artificial intelligence aspects of games. The conference had two sessions on procedural content generation (PCG) alone, and I met multiple people with a background in mathematics or computability theory. This was not surprising given the type of research that was presented: during the poster session I saw posters about search spaces, generator expressivity, modal logic, and optimization, among other topics. Other than that, the conference had special sessions about esports and opponent matchmaking.
The majority of the participants seem to be from the digital games industry, although there were some board game related talks. For example, Hamna Aslam gave a very useful tutorial about playtesting board games on Wednesday.
¶Industry day and demo session
The conference opened with the industry day on Tuesday, with about 450 visitors from both academia and the games industry. The subsequent days had about 250 visitors.
During this first day, the social media coverage was so extensive that I decided not to livetweet during this conference. However, in the days after, the amount of tweets decreased. It seems that on average games industry people are more active on Twitter than researchers.
I was particularly interested in meeting people during industry day, as I wanted to talk to people from the gaming industry to find out whether they would be interested in using text generation for writing game content. I’ve visited local game developer meetups in the past, but that was a very different crowd than I encountered at COG. I met people from game development companies from all over the world (albeit mostly from Europe), including giant game publishers like Microsoft and Sony.
I was at COG to demonstrate headline generator Churnalist, and the demo session was planned during industry day. Although I already presented a system description paper at ICCC this year, this was the first event where people could try out the system themselves.
I extended Churnalist with a Flask (Python) back-end and a Javascript front-end, to make sure that it was a bit more user-friendly than the bare-bones version. Although it is meant as a human-computer co-creation tool, I programmed the demo in such a way that it could run without any user interaction. On startup, the system generates 50 headlines and showcases them in a web page with a CNN-style news ticker. I used the call for papers of COG as input for the generator, so the headlines included phrases like 'high-profile industry', 'academic leaders', artificial intelligence' and 'procedural generation'. Whenever people wanted more details, I could show them the interactive elements that turn Churnalist into a writing support tool for game writers.
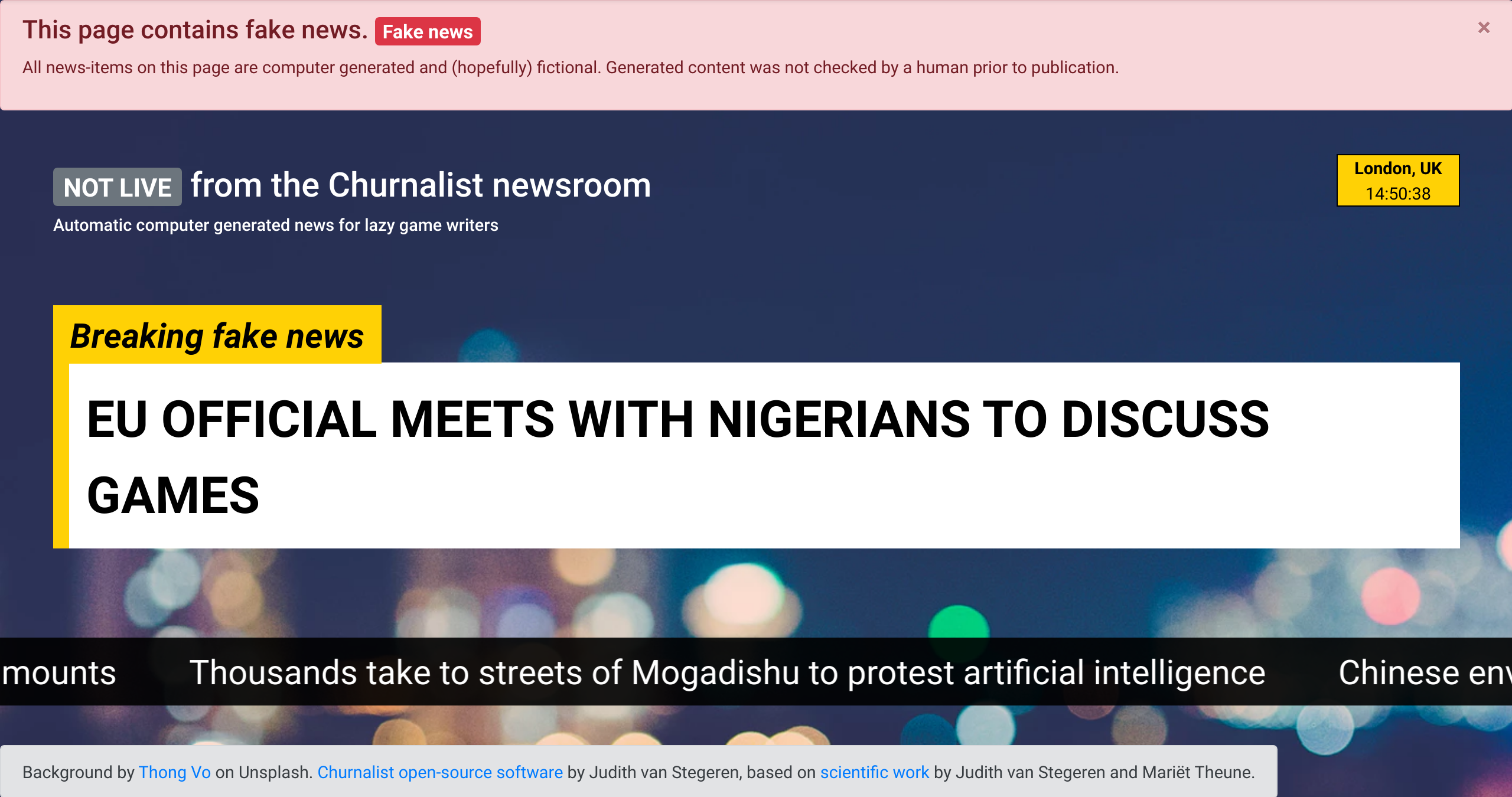
Visitors of the demo session seemed to appreciate Churnalist and its possible applications (the newspaper flavour text from Deus:Ex is one of my favorite examples), and I had multiple conversations with interested researchers and developers. Antonios Liapis stopped by and mentioned the Fantasy Newsroom Bot, a twitter bot that tweets fake news in a fantasy setting. If you stopped by during the demo session: it was great to talk to you, and thank you for all your suggestions and questions.
As an added bonus, the demo of the “fake news generator” made it easier for people with similar interests to spot me later at the conference. Well done to the organizers for planning the demo session relatively early in the conference.
A static version of the demo, with pre-generated content, can be viewed here. The headlines are based on a description of the bachelor programme Creative Technology at the University of Twente.
¶Research highlights
Javier Torres, whom I met last year at FDG, presented a poster about modeling NPCs (agents) and their speech goals with logic. The idea was that agents can’t just reason about their own goals and speech acts, but also about those of other agents. In other words, they can choose to lie, but also find out that other NPCs are lying because there are logical inconsistencies in their speech!
Guenter Wallner had a poster about analyzing Twitter data to find different categories of gamers on social media. I’m always interested in seeing NLP research applied to social media data (a popular topic also at ACL this year). Besides that, the poster mentioned a way of measuring topical coherence in texts, which has interested me ever since I tried to judge the coherence of NaNoGenMo novels.
Mike Cook (whom I finally met IRL at COG after many exchanges on Twitter) gave a very clear talk about smoothing for monotonic generator functions. I have to set aside some time to ponder how we can use this for text generators. The talk can be viewed here: it is the first talk in the session on PCG and AI for Game Design.
Ahmed Khalifa presented a word game called ELIMINATION, in which the challenges are generated with PCG. The talk was interesting, and I also loved the art style of both the game and the slides (see the paper for examples). I liked how the procedurally generated content was evaluated in a realistic game context -- as it should be! This talk made me realise that COG is probably a good fit for my future research, as I’m planning on implementing a game so I can evaluate my generated texts in a representative environment. The talk can be viewed here: it is the fourth talk in the session on PCG and AI for Game Design.
Joshua Sirota presented about procedurally generated grounded languages for NPCs. He created a set of agents (neural networks) that learn a language by playing a referential game, with reinforcement learning for the learning. Although the title reminded me of work by Mark R. Johnson, who generated procedural language for his game Ultima Ratio Regum, this work is fundamentally different because the language is grounded, i.e. the agents try to learn the meaning of language as it applies to the "physical" world they can "see". The talk can be viewed here: it is the fifth talk in the session on PCG and AI for Game Design.
Dan Ashlocke and Vanessa Volz have started a special taskforce on player evaluation. They are bringing researchers together to work on standardized metrics for evaluating player experience and game content. I have joined their mailing list, as I want to investigate how we can evaluate textual game content, such as narratives and dialogue. If you want to contribute as well, contact one of the organisers.
Christoffer Holmgård of modl.ai gave a talk about the research gap between academia and industry in the video games domain.
¶Keynote by Emily Short (natural language and games)
The absolute highlight for me was the keynote by Emily Short, titled “Natural language and games”. Short works as Chief Product Officer at Spirit AI (London), which develops tools for natural language understanding and natural language generation, specifically for games. Their main product is the Character Engine, an authoring tool for game development. It can be used to generate dialogue, or to support a human game writer. It can also be used to build games with natural language understanding (think of the text input of games like Zork).
When creating dialogue, the system keeps track of various aspects of the conversation: where we are in the global narrative, what the emotions of the speakers are, and what we know about the world in which the dialogue takes place. The Character Engine uses a list of classifiers for detecting various kinds of speech acts and conversational intents. It can be expanded with additional classifers to tailor to specific projects or domains.
Short talked about an experiment Spirit AI did to test their bot with real humans. The experiment involved two sets of participants: the first was a group of 1800 beta testers, and the second was a group of trade show visitors at GDC. Both groups interacted very differently with the bot.
The beta testers used shorter phases and ‘played’ multiple times. Surprisingly, they were also a lot more abusive towards the bot. The trade show visitors used longer and more varied sentences, and interacted with the bot for shorter periods of time. Their language also contained more typos. Because of these results, Short advises playtesting NLU games with a large number of people, so the bot can be tested on a large variety of users and inputs.
The keynote went beyond a regular “We developed thing X, this is how it works” talk. Towards the end, Short discussed the difficulties in applying natural language processing and generation for games. Games differ in a few aspects from the usual applications of NLG:
- Real world information might not be applicable in the game world, and thus strategies for finding answers to out-of-domain questions might not work.
- the player/user/reader is role-playing, which means that they have a different type of interaction than regular chatbots have with their users, such as a person has with a customer support chatbot.
- There’s a larger variety in interaction styles: the NPC chat bot has to be able to mix functional questions (“How are you doing? Is grass green?”) with narrative moments to bring the story forward (the bot/NPC wants to introduce a certain quest line) and act in a believable way according to the NPCs goals and emotions (the bot is playing an alien from planet Y that doesn’t trust the player yet). All these types of interaction depend on different dialogue parameters and different NLG techniques.
In other words: problems that might be trivial to solve for a customer service chatbot could be complex when developing an NPC bot.
Short also mentioned an unsolved problem in sentiment analysis research, one that I have encountered in my own projects as well. If we want to develop sentiment analysis tools for games, we need a classifier that is tailored to the gaming context. However, a proper model for this context is hard to create, as most sentiment analysis research is focused on (and thus biased towards) product reviews. Most of the datasets that are used to train and evaluate sentiment analysis tools are crowd sourced product review datasets, for example from Netflix, Amazon, etc.
We really need open-source language models for sentiment analysis that can generalize to different domains, including game-playing and fictional game worlds. I'm currently working with Lorenzo Gatti to solve this problem for Dutch. We are trying to improve Pattern.nl, an NLP library for Dutch that also contains sentiment analysis functionality.
¶Keynote by James Dean (esports and WEAVR)
The conference ended with a keynote by James Dean, the founder of the UK division of the Esports League (ESL). I wasn’t familiar with the professional esports world, and it was nice to get an overview of the activities of the ESL. Esports are fundamentally different from traditional sports, notably in terms of monetization: only 15% of esports funding comes from advertising. The ESL is involved in a research and development project called "WEAVR" together with the University of York. The project tries to find new ways of engaging the audience during sports matches, as methods from traditional analog sports are not really suitable for esports. The project tries to incorporate VR, personalized information, adaptivity, and augmented reality.
Dean urged academia to put more effort into connecting with industry. People working in industry generally don't read scientific articles, so relying on publications to bring your research findings to people outside academia is not enough. York University used an industry outreach project to connect with ESL, which led to the collaboration.
¶Conclusion
COG was an enjoyable conference, where I encountered a lot of the usual suspects from FDG and ICCC and met loads of interesting new people. Especially if you’re looking to discuss your technical ideas with people from both industry and academia, this is a good conference to visit.
My estimate is that it will be a good fit for my future research. I haven’t done much research with digital games yet, as games are only a possible application of my work in natural language generation. Next year I plan to evaluate Churnalist in a games context, either with users, writers, or both. Another idea I have is to write a small game and use it to test the basic assumptions on which I build NLG tools. Both lines of research would fit nicely in COG’s program, so I’m sure I will visit this conference again.
The organisation has recorded all talks. Once they are uploaded, I will update this blogpost with links to the talks. You can find the proceedings here.
If you want to talk about any of the stuff above, send me a message on Twitter!
Thanks to Ruud de Jong for proof-reading this post. :)